LS100 Guide
Data Careers: Navigating the Evolving Data Landscape
A field guide for students and early-career professionals
Souvik Mandal, Ph.D., Linkedin ID: souvik-mandal-phd
Project Leader & Instructor, Computational Behavioral Sciences, LS100, FAS, Harvard University
Data is the core raw material of most modern businesses, driving operational efficiency, product innovation, and strategic decision-making. As a result, the ecosystem of data-focused professions has grown rapidly and become highly specialized. The recent rise of generative and agentic AI is reshaping it again. This guide helps college students and early-career professionals understand the distinctions between these roles, the technical proficiencies each requires, and where the field is heading in my opinion. It also shows how the skills you build in LS100 map onto these careers and how to present them on your CV and résumé.
The Industry Data Pipeline:¶
To understand where specific jobs fit, it helps to look at the industry data pipeline — the lifecycle of how data is produced, stored, and ultimately consumed. Almost every data role exists to support one of these three stages.
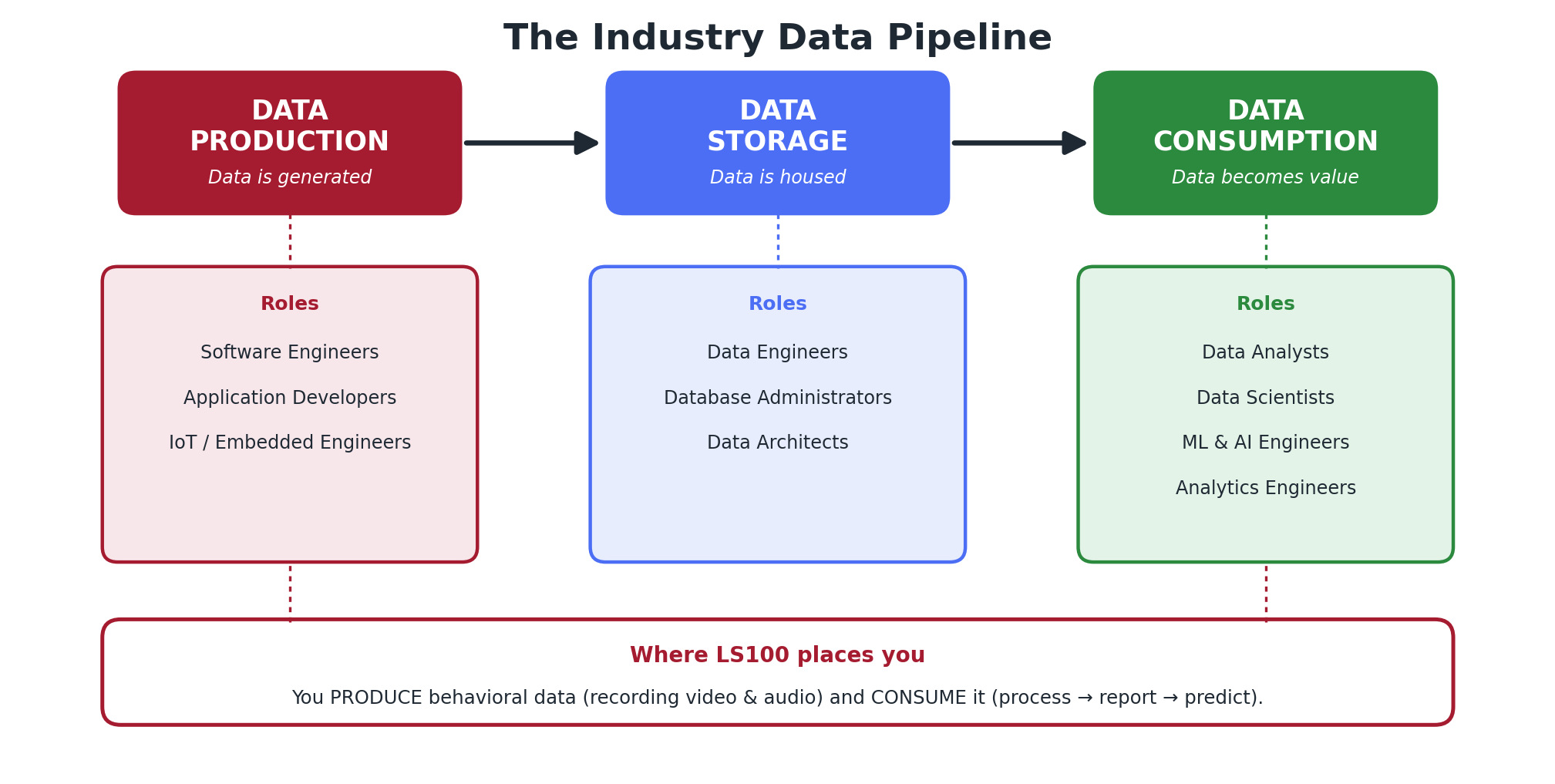
Figure 1. The data lifecycle and the roles that support each stage.
Data Production¶
In a hyper-connected digital economy, almost every business service, production line, and retail purchase happens over or interacts with the internet, generating massive, distinct streams of raw data. Every click, scrolling, transaction, and sensor reading adds to this data.
Everything runs over the internet — services, manufacturing and IoT-instrumented production lines, and retail / e-commerce all leave digital traces.
Different sectors, different data — finance (transactions, risk signals), healthcare (electronic health records, wearables, medical imaging), and entertainment (streaming and viewing behavior) each produce their own data types.
Customer interaction and history — clickstreams, searches, support tickets, and CRM records accumulate into rich behavioral profiles.
Data as wealth — much of the last two decades’ largest technology-sector wealth creation (Google, Meta, Apple, Microsoft, Amazon) was built on collecting and monetizing user data.
Internal and operational data — application logs, sensor telemetry, and finance / HR systems are data sources in their own right.
In this course: If you have recorded video and/or audio of human or animal subjects, you have produced raw behavioral data. Choosing the frame rate, microphone placement, and annotation schema are all data-production decisions.
Associated roles: Software Engineers, Application Developers, IoT / Embedded Systems Engineers.
Data Storage¶
Once data is produced, it must be housed safely, reliably, and at scale. Organizations manage this through physical or virtual repositories, increasingly in the cloud. How data is stored and how quickly it can be retrieved shapes everything downstream, from the queries an analyst can run to the models an engineer can train. Good storage design also protects sensitive data and keeps it recoverable after failures.
Databases vs. warehouses vs. lakes: Different data storage systems, or databases, are used to store different types of data.
Operational Databases (OLTP): The main architecture used to store “live”, day-to-day operations and actions data (like orders or transactions, represented as numbers and short text) is Online Transaction Processing (OLTP). These data are structured on strictly pre-defined schema and stored in a table format, typically the columns representing fields and rows representing records (customer, transaction, etc.). These systems manage real-time business transactions. Examples of commercial vendors include PostgreSQL, MySQL, Microsoft SQL Server, Oracle DB, etc.
Data Warehouses (OLAP): Along with facilitating the operation, these raw data are also periodically extracted, transformed, and loaded (ETL) into Online Analytical Processing (OLAP) systems. A Data Warehouse is an OLAP system optimized specifically for high-performance analytical queries and business intelligence. Examples of commercial vendors include Snowflake, Google BigQuery, and Amazon Redshift.
Data Lakes: When organizations need to store massive volumes of raw, unstructured, or semi-structured data, traditional rigid tables fail. This includes media assets like video and music files for streaming services (such as Netflix or Spotify), or raw files for cloud storage services like Google Drive and Dropbox. A data lake stores these files in their native, raw formats without forcing a predefined schema. Examples of commercial vendors include Amazon S3, Google Cloud Storage, Azure Blob Storage, and Apache Hadoop.
Data Lakehouses: This modern paradigm represents a convergence of engineering disciplines. A data lakehouse implements data warehouse management features (like ACID transactions, data versioning, and query optimization) directly on top of the low-cost, flexible storage of a data lake, allowing data scientists and analysts to query raw media and structured logs in the same environment. Examples of commercial vendors include Databricks (utilizing Delta Lake) and Snowflake (via Apache Iceberg integration).
In this course:.
Formats and structure — structured tables, semi-structured JSON, and efficient columnar formats such as Parquet each suit different needs.
Security, governance, and backup — stored data must be access-controlled, encrypted, and recoverable.
In this course, you may have uploaded raw audio or video files into a cloud drive or shared directory. You have also automated data formatting and naming data files following a schema, organized data into clearly labeled folders, saved feature tables as CSV files, chose appropriate file formats, and wrote a data-management plan – these are all data storage practices in miniature. Understanding whether data is structured (tables) or unstructured (media files) determines which database architecture you will select in the workforce.
Associated roles: Data Engineers, Database Administrators (DBAs), Data Architects.
Data Consumption¶
Data consumption is where raw assets are turned into tangible value. This is the stage most students will work in first, and it splits into three escalating activities — processing the data, reporting on it, and predicting from it. Each step extracts more value, and each maps to a familiar part of this course.
Processing — raw data is cleaned, transformed, and turned into features (for example, extracting pose keypoints or audio features and engineering kinematic metrics).
Reporting — descriptive analytics, dashboards, and visualizations communicate what happened (for example, plotting joint-angle time series or behavioral ethograms).
Prediction — statistical and machine-learning models forecast or classify (for example, classifying behaviors from pose sequences or modeling repeated-measures data).
In this course: consumption is most of LS100 — Modules 01A/01B handle processing and feature extraction, Notebook 03 covers reporting and visualization, and Module 02 covers statistics and prediction.
Associated roles: Data Analysts, Data Scientists, ML Engineers, AI Engineers, Analytics Engineers.
Data Roles, From the Consumer End to the Infrastructure End¶
The roles below are ordered the way you are most likely to encounter them in your own journey: starting at the consumption that you already relate to — analysts who interpret historical data and scientists who predict from it — and moving upstream toward the engineers, administrators, and architects who build and govern the systems.
1. Data Analyst¶
Data Analysts are the translators between technical data repositories and business stakeholders. Their primary objective is to evaluate past and current performance to uncover actionable insights, answering specific business questions with descriptive and diagnostic analytics.
Core Responsibilities: Querying databases to extract information, cleaning data for analysis, performing exploratory data analysis (EDA), and building dashboards to track key performance indicators (KPIs).
Typical Day-to-Day: Writing SQL queries to generate weekly performance reports, updating Tableau or Power BI dashboards, meeting with product or marketing teams to gather requirements, and summarizing findings into slide decks — increasingly with AI assistants drafting first-pass queries and summaries.
Key Tools: SQL, Excel, Tableau, Power BI, Python (Pandas, NumPy), R.
2. Data Scientist¶
Data Scientists leverage advanced mathematics, statistics, and machine learning to build predictive models and algorithms. While analysts focus on what happened, data scientists focus on predicting what will happen and on optimizing complex processes.
Core Responsibilities: Designing experimental frameworks (such as A/B tests), engineering data features, training and tuning machine-learning models, and conducting deep statistical analysis to answer question that are more complex than that can be answered through usual analyses.
Typical Day-to-Day: Formulating hypotheses, writing Python in Jupyter notebooks to train algorithms, validating model accuracy against baselines, and presenting experimental methodology to leadership.
Key Tools: Python, R, SQL, scikit-learn, TensorFlow, PyTorch, Jupyter, Git.
3. Machine Learning (ML) Engineer¶
Machine Learning Engineers sit at the intersection of data science and software engineering. Their focus is taking the models developed by data scientists and deploying, scaling, and maintaining them reliably in production.
Core Responsibilities: Translating prototype models into production-ready code, designing MLOps pipelines for continuous training and deployment, optimizing model latency, and monitoring production systems for model drift.
Typical Day-to-Day: Containerizing a model with Docker, deploying it to a Kubernetes cluster, setting up real-time inference API endpoints, and building dashboards to track prediction performance.
Key Tools: Python, Docker, Kubernetes, MLflow, Kubeflow, cloud AI platforms (AWS SageMaker, Google Vertex AI), CI/CD pipelines.
4. AI / Generative AI Engineer¶
AI Engineers build applications on top of large pre-trained foundation models rather than training models from scratch. Where a data scientist asks “what will happen,” an AI engineer asks “how do I turn a powerful model into a reliable product feature?” It is the fastest-growing data role of the mid-2020s, with demand and salaries rising sharply as companies race to ship AI features.
Core Responsibilities: Integrating large language models (LLMs) via APIs, building retrieval-augmented generation (RAG) pipelines over vector databases, designing and orchestrating AI agents, engineering and evaluating prompts, and managing hallucination, latency, and cost.
Typical Day-to-Day: Connecting an LLM to a company knowledge base with embeddings and a vector store, building an agentic workflow with a framework such as LangChain or LlamaIndex, writing evaluation harnesses to measure answer quality, and hardening an inference endpoint for production traffic.
Key Tools: Python, LLM APIs (OpenAI, Anthropic, open-weight models), LangChain / LlamaIndex / LangGraph, vector databases (Pinecone, Weaviate, FAISS, pgvector), Hugging Face, Docker.
5. Analytics Engineer¶
A relatively modern role, the Analytics Engineer bridges data engineering and data analysis. They apply software-engineering best practices — version control, testing, modularity — to the transformation layer, ensuring clean, trustworthy datasets are available to end-users.
Core Responsibilities: Modeling data within cloud warehouses, writing robust transformation logic, implementing automated data-quality tests, and documenting data lineage.
Typical Day-to-Day: Writing modular SQL with dbt (data build tool), opening pull requests to update data models, setting up alerts for data-quality failures, and training analysts to use newly structured tables.
Key Tools: SQL, dbt, Git, Snowflake, Databricks, BigQuery.
6. Data Engineer¶
Data Engineers design, construct, and maintain the foundational infrastructure that lets data flow seamlessly through an organization. They build the pipelines and architectures that keep data clean, reliable, and accessible to analysts and scientists.
Core Responsibilities: Developing Extract-Transform-Load (ETL) or ELT pipelines, orchestrating data workflows, optimizing queries for scale, and managing distributed computing environments.
Typical Day-to-Day: Writing Python or Scala to process massive datasets, debugging a failed pipeline in Apache Airflow, scaling a cloud warehouse instance, and ensuring the architecture meets schema standards.
Key Tools: SQL, Python, Scala, Apache Spark, Apache Kafka, Airflow, Snowflake, BigQuery, AWS/GCP data tools.
7. Database Administrator (DBA)¶
Database Administrators focus on the operational health, security, and performance of database management systems. While engineers move data around, DBAs keep the central databases stable, responsive, and secure.
Core Responsibilities: Managing access controls and security permissions, configuring backups and disaster-recovery plans, tuning database configurations, and ensuring maximum uptime.
Typical Day-to-Day: Monitoring performance logs, indexing slow transactional tables, restoring a database from backup to test disaster recovery, and patching database software for security vulnerabilities.
Key Tools: Oracle DB, Microsoft SQL Server, PostgreSQL, MySQL, Linux/Unix scripting.
8. Data Architect¶
Data Architects are senior strategists who design the overarching blueprint for an organization’s entire data-management framework. They define how data is collected, integrated, protected, and maintained across the corporate infrastructure.
Core Responsibilities: Developing enterprise-wide data strategies, designing logical and physical data models, establishing governance standards, and aligning technical infrastructure with long-term business goals.
Typical Day-to-Day: Collaborating with executive leadership on IT roadmaps, evaluating vendors for cloud migrations, mapping entity-relationship diagrams, and reviewing architecture designs with engineering leads.
Key Tools: ERwin Data Modeler, Kimball methodologies, cloud architecture frameworks, data-governance platforms.
Comparative Analysis of Roles¶
The table below compares the core professions side by side across primary focus, languages, technical emphasis, and key stakeholders.
| Role | Primary Focus | Core Languages | Key Technical Focus | Primary Stakeholders |
| Data Analyst | Descriptive / historical insight | SQL, Python | BI dashboards, KPI reporting | Business units, product managers |
| Data Scientist | Predictive / advanced analytics | Python, R, SQL | Statistical models, machine learning | Product teams, R&D leadership |
| ML Engineer | Model deployment & scale | Python, C++, Java | MLOps, containerization, latency | Data scientists, software engineers |
| AI / GenAI Engineer | LLM-powered applications | Python | RAG, agents, prompting & evaluation | Product teams, software engineers |
| Analytics Engineer | Data transformation & quality | SQL, Python | Data modeling, dbt testing | Data analysts, business users |
| Data Engineer | Data infrastructure & pipelines | Python, SQL, Scala, Java | ETL/ELT, distributed computing | Analysts, scientists, architects |
| Database Administrator | Database health & security | SQL, Bash/Shell | Backup/recovery, performance tuning | IT security, infrastructure teams |
| Data Architect | Enterprise data strategy | SQL (conceptual) | Data modeling, enterprise blueprints | CTO/CIO, engineering directors |
Entry-Level Competency and Expectations¶
Breaking into the data ecosystem requires a mix of foundational knowledge, specialized practical skills, and soft skills. Entry-level expectations vary by role, but a common base is expected everywhere.
Foundational competencies (expected across all roles)¶
SQL proficiency — an absolute prerequisite; understand joins, aggregations, window functions, and subqueries.
Programming fundamentals — comfort with at least one scripting language (usually Python) plus data structures, algorithms, and modular programming.
Version control — the mechanics of Git (cloning, branching, committing, pull requests) are standard practice.
AI-assisted workflows — fluency with AI coding assistants and the judgment to verify, debug, and improve their output is now a baseline expectation, not a bonus.
Role-specific expectations¶
Entry-Level Data Analyst: a portfolio that takes a messy dataset, cleans it, extracts an insight, and presents it in a clear dashboard. Communication and presentation skills are heavily weighted.
Entry-Level Data Scientist: strong mathematical foundations — the assumptions of linear and logistic regression and decision trees, plus probability and statistical significance (p-values, confidence intervals). A rigorous project portfolio can substitute for an advanced degree.
Entry-Level Data / Analytics Engineer: algorithmic thinking and clean software design — data structures, database normalization, file formats (Parquet, JSON, CSV), and a firm grasp of cloud fundamentals.
Entry-Level AI Engineer: the ability to call an LLM API, build a basic RAG pipeline over a vector store, and reason about prompts, evaluation, latency, and cost — demonstrated through a working demo.
The Future Trajectory of Data Jobs¶
The data domain changes rapidly with technological breakthroughs and shifting infrastructure trends. A few developments are shaping the next several years of data careers.
The Impact of Generative and Agentic AI¶
Generative AI is reshaping standard analyst and developer tasks. Routine work — boilerplate SQL, basic Python scripts, code documentation — is increasingly drafted by AI coding assistants, and agentic AI systems are beginning to chain such tasks together autonomously. The human focus is shifting away from syntax execution toward architecture, strategic problem framing, data governance, and the integration of LLMs into production systems via vector databases and retrieval-augmented generation (RAG). One concrete result is the emergence of the AI Engineer as a distinct, high-demand role.
Convergence of Engineering Disciplines¶
The line between data engineering and traditional software engineering is narrowing. Modern data stacks expect software paradigms — CI/CD, unit testing of data, infrastructure-as-code, and rigorous monitoring. Professionals who treat data systems with a software-engineering mindset remain in high demand.
Data Governance, Ethics, and Privacy¶
With regulations such as GDPR, CCPA, and the EU AI Act, and rising awareness of algorithmic bias, organizations place increasing weight on governance and compliance. Future data professionals must understand data lineage, masking, secure access patterns, and the ethical implications of training models on user data.
Strategic Roadmap for Students¶
Building a data career involves deliberate choices during your academic years and good positioning as you enter the job market.
Actionable strategies during college¶
Curriculum selection — build a cross-disciplinary base: computer science (data structures, databases), statistics (probability, applied regression), and business or economics (how companies operate and measure success).
Build a dynamic portfolio — avoid generic tutorial datasets (Iris, Titanic). Scrape original data, connect to public APIs, or analyze local government data — and include at least one AI/LLM project. Publish documented code on GitHub and write up your insights on Medium or LinkedIn.
Pursue internships and applied projects — theory cannot match real-world context; join data clubs or offer pro-bono analysis for local non-profits to practice working with stakeholders.
Participate in collaborative events — hackathons, data-thons, and Kaggle competitions build collaboration skills and expand your network.
Transitioning and upskilling after college¶
Target early-career paths — rotational programs let recent graduates experience multiple data teams over 1–2 years before specializing.
Strategic certifications — credentials can signal specialized knowledge. Valuable targets include the AWS Certified Data Engineer – Associate (which replaced the retired AWS Data Analytics – Specialty in 2024), the Google Cloud Professional Data Engineer, and tool-specific credentials such as dbt and Snowflake.
Commit to continuous upskilling — set aside weekly time to read engineering blogs from data-driven companies, for example Netflix, Airbnb, and Uber.
From LS100 to Your Résumé¶
The work you do in LS100 is genuine, portfolio-grade data experience — you collect raw data, build reproducible pipelines, extract features, model, and communicate results. The key is to describe it in the language recruiters scan for. Below are résumé-ready bullets you can adapt from your own projects (replace the specifics with your data and numbers).
Built reproducible Python pipelines to extract 2D/3D pose keypoints from video using YOLO and MediaPipe; engineered joint-angle and kinematic features for downstream modeling.
Processed digital audio, extracting spectral and rhythmic features, and clustered audio data with k-means / HDBSCAN, visualized via PCA and UMAP.
Trained and evaluated sequence-classification models on behavioral time series, reporting precision, recall, and confusion matrices.
Validated and reported findings with classical statistical tests and linear mixed-effects models on repeated-measures data.
Communicated results through publication-quality visualizations (Matplotlib, seaborn, Plotly) and maintained documented, version-controlled code on GitHub.
Which course skills signal which role¶
Data Analyst — exploratory data analysis, pandas, and clear visual reporting (Notebooks 01–03).
Data Scientist — experimental thinking, statistics, and ML modeling (Module 02 and the classification notebooks).
ML / AI Engineer — reproducible pipelines, model training, and object-oriented code (Modules 01A/01B and the classes notebook).
Data / Analytics Engineer — data wrangling, automation, and careful file/format handling (Notebooks 02 and 04).
Data Careers in Research and Academia¶
LS100 is a research course, and the same computational skills open doors well beyond industry data teams.
Quantifying behavior from video, audio, and digital records is exactly the skill set that powers modern research labs. Students who enjoy this work often head toward research-facing roles rather than (or before) industry:
Research Data Scientist — applies the same modeling and statistics inside universities, hospitals, and research institutes.
Computational ethologist / quantitative behavioral scientist — uses pose estimation and machine learning to study animal and human behavior at scale.
Bioinformatician / computational biologist — applies pipelines and statistics to biological and neural data.
Research software engineer / lab data manager — builds and maintains the reproducible tools and datasets a lab depends on.
These paths reward exactly what LS100 emphasizes — reproducibility, sound statistics, and domain understanding — and they are common stepping stones to graduate study in computational biology, neuroscience, or data science.